JavaScript中的数据类型分为两大类:原始数据类型和引用数据类型。
- 原始数据类型的数据保存在栈内存中
- 引用数据类型的数据保存在堆内存中,其在栈内存中存储的是引用数据类型值在堆内存中的地址
深拷贝和浅拷贝只是针对引用数据类型而言的。
浅拷贝
浅拷贝指的是创建新的数据,这个数据有着原始数据属性值的一份精确拷贝。
如果属性是基本数据类型,拷贝的就是基本类型的值,如果属性是引用数据类型,拷贝的就是地址。
浅拷贝是拷贝一层,深层次的引用类型则是共享内存地址。
一个简单的浅拷贝代码:
1
2
3
4
5
6
7
8
9
| function shallowClone(obj){
const newObj = {};
for(let prop in obj){
if(obj.hasOwnProperty(prop)){
newObj[prop] = obj[prop];
}
}
return newObj;
}
|
在JavaScript中,存在浅拷贝的现象有:
Object.assign()Array.prototype.slice()Array.prototype.concat()- 使用拓展运算符实现复制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
var obj = {
name:'Jack',
age:18,
grade:'seven',
doSomething:{
type1:'baseball',
type2:'swimming'
}
}
var newObj = Object.assign({},obj);
const arr1 = ['one','two','three'];
const newArr1 = arr1.slice(0);
const arr2 = ['one','two','three'];
const newArr2 = arr2.concat();
const arr3 = ['one','two','three'];
const newArr3 = [...arr3];
|
深拷贝
深拷贝开辟一个新的栈,两个对象属性完全相同,但是对应两个不同的地址,修改一个对象的属性,不会改变另一个对象的属性
常见的深拷贝的方法有:
_.cloneDeep()jQuery.extend()JSON.parse(JSON.stringfy())- 手写循环递归
☀️_.cloneDeep()
1
2
3
4
5
6
7
8
| const _ = require('lodash');
const obj1 = {
a:1,
b:{f:{g:1}},
c:[1,2,3]
};
const obj2 = _.cloneDeep(obj1);
console.log(obj1.b.f === obj2.b.f);
|
☀️jQuery.extend()
1
2
3
4
5
6
7
8
| const $ = require('jquery');
const obj1 = {
a:1,
b:{f:{g:1}},
c:[1,2,3]
};
const obj2 = $.extend(true,{},obj1);
console.log(obj1.b.f === obj2.b.f);
|
☀️JSON.parse(JSON.stringfy())
1
2
3
| const obj2 = JSON.parse(JSON.stringfy(obj1));
|
但是这种方式存在弊端,会忽略undefined、symbol和函数
1
2
3
4
5
6
7
8
| const obj = {
name: 'A',
name1: undefined,
name3: function() {},
name4: Symbol('A')
}
const obj2 = JSON.parse(JSON.stringify(obj));
console.log(obj2);
|
使用JSON.parse(JSON.stringfy())的弊端:
①数据中包含function,undefined, Symbol这几种类型(不可枚举属性),JSON.stringfy序列化之后,会丢失
②数据中包含NaN、Infinity、-Infinity,JSON.stringfy序列化之后的结果是null
③数据中包含Date对象,JSON.stringfy序列化之后会变为字符串
④数据中包含RegExp(正则表达式),序列化之后会变成空对象
⑤map/set集合,无法序列化
☀️循环递归
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| function deepClone(obj) {
const map = new WeakMap()
const dp = (obj) => {
if (!isObject(obj)) return obj
if (map.has(obj)) return map.get(obj)
map.set(obj, Array.isArray(obj) ? [] : {})
const fn = obj.constructor
if (fn === RegExp) {
return new RegExp(obj)
}
if (fn === Date) {
return new Date(obj.getTime())
}
if (fn === Function) {
return obj.bind({})
}
if (Array.isArray(obj)) {
const newObj = []
for (const v of obj) {
newObj.push(isObject(v) ? dp(v) : v)
}
map.set(obj, newObj)
return newObj
}
if (isObject(obj)) {
const newObj = {}
Reflect.ownKeys(obj).forEach(k => {
const v = obj[k]
newObj[k] = isObject(v) ? dp(v) : v
})
map.set(obj, newObj)
return newObj
}
}
return dp(obj)
}
|
二者区别
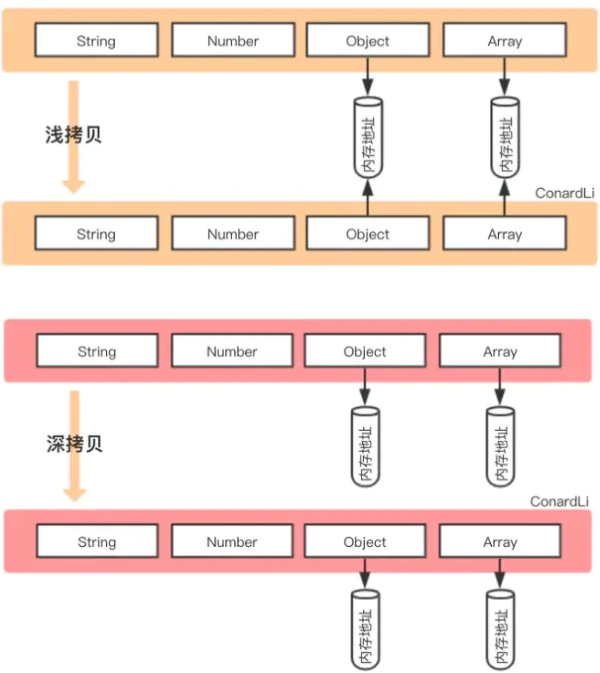
从上图中可以发现,深拷贝和浅拷贝都是创建出一个新的对象,但在复制对象属性的时候,行为不一样。
浅拷贝只复制属性指向某个对象的指针,而不是复制对象本身,新旧对象还是共享一块内存,修改对象属性会影响原对象。
但是深拷贝会另外创造一个一模一样的对象,新对象和旧对象不共享内存,修改对象不会影响原对象。
小结
前提是 拷贝类型为引用类型 的情况下:
- 浅拷贝是拷贝一层,属性为对象时,浅拷贝是复制,两个对象指向同一个地址
- 深拷贝是递归拷贝深层次,属性为对象时,深拷贝是新开栈,两个对象指向不同的地址
